
My experience with Multi-Account Architecture
This is post 2 of 9 in a multi-part series (hosted here) discussing the advantages, pitfalls, deployment methodology, and management of a multi-cloud account architecture. For this series, we are focusing strictly on using AWS as the Cloud Service Provider (CSP) but the concepts discussed port well to any provider or even to on-premise operations.
Background
The context provided in the previous post is not hypothetical. It is the reality I faced within about three months of starting enterprise cloud work for a new organization. Prior to this transition in mid-2016, I had some experience with cloud. Since late 2011 I had been exploring Microsoft Azure App Services, Databases, Storage Accounts, and virtual machines. But nothing at enterprise scale. From 2012 to 2014 I had deployed some web and mobile applications using the Azure App Services Stack, built up a very small user base, and began exploring Amazon’s suite of cloud services to do the same thing. This was more for curiosity sake than it was for job requirements. At the time I was being paid to be a Windows Systems Administrator. Anything I did in the cloud was for my own career advancement and self-interest.
In early 2016 I was ‘presented’ an opportunity to explore using AWS S3, Storage Gateway, and Virtual Tape Library for enterprise cloud backup. I say ‘presented’ because I really sought the opportunity myself regardless of who wants to take credit. Granted, had I not been afforded the opportunity, my rapid transition into cloud architecture would not have happened at the pace it did. I would have still gotten here, just maybe not as quickly and with the knowledge I plan to share throughout the rest of this series.
After exploring and deploying enterprise cloud backup for a bit, I was pulled completely into the cloud program. That is where shortly after the team was broken into two. An operations team and a design team. I was asked to lead the operations team. Not because of my experience in the cloud yet but more so because I was the most ‘senior level’ as well as most outspoken or opinionated.
At this time the discussion was to create as few AWS accounts as possible. These accounts were to provide managed services to allow the enterprise to leverage the cloud in a very scalable, yet manageable fashion. This was due to manpower experience as well as the ability to pay for more people. How could we manage even a half-dozen accounts with so few support personnel?
The current configuration
Before I go any further with the transition to as few accounts as possible to literally hundreds, I need to briefly explain the current architecture configuration.
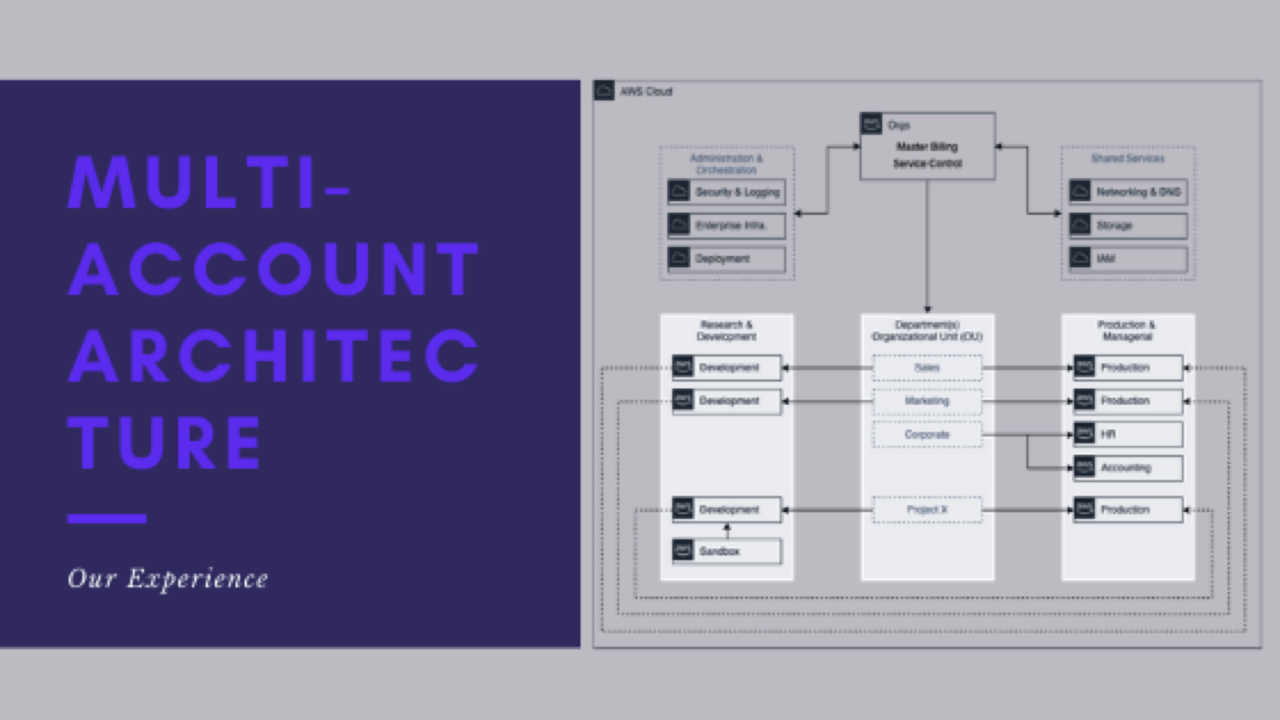
The goal was to give individual development teams the freedom to create cool and innovative things in the cloud. All the while segmenting cost and not bumping into other development teams working completely different and unrelated projects. There was a primary account for managing Cloud Active Directory, Web Application Firewall, Ingress/Egress, and a few other enterprise security tools. The rest of the architecture was dedicated to letting anyone with a new application or idea to leverage the cloud. The team that I was a part of was charged with keeping strict baselines, securing all the accounts, and supporting the developers by enabling ‘approved’ AWS services. The organization’s initiative as a whole became ‘cloud-first.’ Anything new, any request for new hardware first had to answer the question – Why not go cloud?
‘Cloud’ and “Cloud-First’ meant something different to nearly everyone but when I arrived on the program, there was about a dozen AWS accounts that were all pretty much managed to the best of anyone’s ability at this stage in the game. Lots of drift and nuance from account to account. Nothing was standardized even though team members were under the impression it was. Every ‘production’ application account at the time needed to first have an existing ‘development’ account already deployed and an application accredited to be ‘production’ prior to getting an account to make the application live. In a very short time, any consideration of deploying another AWS account was of high concern. Keeping all the accounts in line and near baseline was virtually impossible.
Furthermore, as we explored how to better manage and scale through the use of shared or managed services, we realized there was no great way to provide the level of service required while being able to break out usage and charges in a productive manner. The ideal that was first 80% managed service accounts and 20% custom developer accounts soon shifted to the inverse. When the team laid out to management the facts and caveats to managing fewer accounts versus more, the reality became clear. The paradigm shifted. We needed to support as many AWS accounts as possible. This is when I was asked, “what do we need to do to support hundreds of AWS accounts while maintaining minimal support staff (a.k.a. my team)?”
Supporting the masses
At this time we still had just over a dozen AWS accounts and beginning to understand the transition to managing many more. Deploying a new AWS account, ‘baselining it’, and providing access to developers took a minimum of two weeks. Since development teams had access limited only to the services we allowed and we prevented any changes to networking configuration for security reasons, changes to any account at the time took anywhere from 1 to 3 weeks. This was due to the fact that we first had to call a CAB, discuss the change, and the responsible parties had to review and implications of the change before manually making that change in the respective accounts.
It’s early 2017 and because of the environment we were in, some of the great services AWS released were not available to us quite yet. Take AWS Organizations for example. A vast majority of the automation we had in place was a hodgepodge of scripts and Jenkins jobs that in some cases cause more issues than they solved. It was a mess. But again, everything was done in good faith and using the best tools and know-how we had at our disposal at the time.
A new mindset
After nearly a year of limping along, supporting a slow growth of AWS accounts, discussing our issues, prioritizing (re)work of processes, and (re)factoring of automation, we decided to take a 3-month break from deploying new accounts to build out our new systems and plan for the future. Throughout the year I researched other organizations, AWS Talks, and Webinars, spoke with team members about what was working and what wasn’t, and I re-evaluated our change management process. I ultimately prioritized with the team what we believed needed to be done in order to support a seemingly infinite amount of AWS accounts with basically a team of no more than 8 support personnel.
During our break from deployment, we built new systems and automation as well as leveraged some AWS services that had recently become available to us. As we reopened the doors and began to deploy new accounts, we quickly realized our new processes had introduced a new problem. We were now able to scale very quickly. Support was still going to be an issue at some point but now we were having Private IP Space issues and running out quickly. Around the same time, we hit a wall with IP addressing, we also hit an undocumented limitation of AWS Transit VPC. Any newly advertised routes into our cloud environment would bring down the network. All the work we had done to deploy cloud accounts quickly and stick them to a baseline was now stuck in its tracks. We solved ourselves into a new problem, even if it was a good problem to have.
AWS to the rescue
It’s now the end of 2018 and time for re:Invent again. Regardless of all the team was able to accomplish as a result of limping along in 2017, the release of AWS Organizations, and the implementation of our new processes and automation resulting from our strategic pause at the beginning of 2018, we were stuck. We manufactured a new problem. Until AWS released Shared VPCs and RAM (or Resource Access Manager).
This opened up many opportunities for the program to meet the needs of any developers looking to work on new projects in the cloud. This new feature released by AWS enabled the team that I was a part of to begin scaling to the number of AWS accounts we were asked to support just 18 months prior.
Sooo… Mission accomplished?
Not quite. Shortly after our implementation of AWS Shared Resources and another refactor of our account deployment process, we found ourselves needing to address many other growing pains. Things like the retirement or upgrade of existing services to cloud-native services as well as the implementation of newly approved services, after evaluating if the meant many different use-case requirements.
Up to this point, the growth trajectory of the program has been insane. So much so that I personally believe organizations of any size would find it impressive. Here are some quick numbers to demonstrate the history of the program.
- Beginning of 2017
- Active Accounts: Approximately 12
- Deployment Time: Greater than 2 weeks
- Permission Roles/Policies: 1
- Change Review Time: 2-3 weeks
- Beginning of 2018
- Active Accounts: Approximately 30
- Deployment Time: Less than 1 week
- Permission Roles/Policies: About 20
- Change Review Time: 1-2 weeks
- Beginning of 2019
- Active Accounts: Greater than 65
- Deployment Time: 30 minutes
- Permission Roles/Policies: 3
- Change Review Time: Virtually in real-time
While I was ‘involved’ with the amazing success of this growth and progress, the team was instrumental in the implementation. I did very little from a technical implementation standpoint. I merely did what I could as a lead to keep things on track, focused, and prevent perceived ‘fires’ from derailing our progress.
In August of 2019, I left this program to pursue other opportunities but I didn’t take leaving lightly. I learned a ton from being part of this team and attribute the following posts in this series to the experience I gained working with the team and that organization.
The following posts in this series do not share any ‘secret sauce’. There isn’t any. The concepts used are well documented in the AWS Multi-Account Security Strategy and the best practices are part of the AWS Well-Architected Framework. Presented here is a unique twist on the lessons learned and the hurdles jumped to be successful in implementing a secure, baselined, and well-documented multi-account cloud architecture.
Series parts are as follows:
-
- Series Introduction
- My experience with Multi-Account Architecture
- What does the end-state look like
- Reasons you might consider multi-account architecture
- When it is right to implement
- What the potential architecture might look like
- How do you get there
- How do you support and maintain the architecture
- Lessons learned








Leave a Reply
Want to join the discussion?Feel free to contribute!