
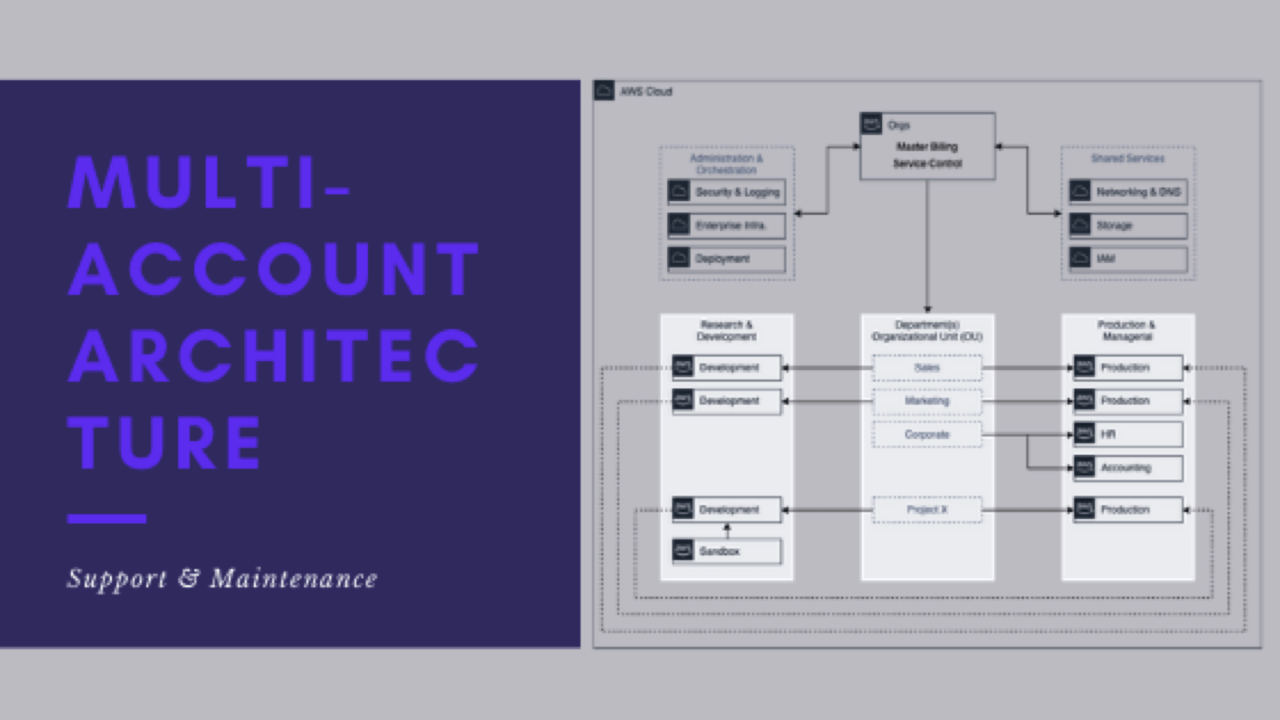
This is post 8 of 9 in a multi-part series (hosted here) discussing the advantages, pitfalls, deployment methodology, and management of a multi-cloud account architecture. For this series, we are focusing strictly on using AWS as the Cloud Service Provider (CSP) but the concepts discussed port well to any provider or even to on-premise operations.
All aboard!
This journey cannot begin until you have everyone on the same page. By this point in the process, the gears should have really started to turn. Your organization can see how a multi-account architecture can really benefit everyone. We’re talking from customer to developer, operations and security, finance as well as stakeholders.
However, ideas can start to run rampant. Egos can go unchecked. Having a solid foundation with extreme flexibility can lead to a lot of carelessness. Now is more important than ever to make sure everyone is following procedure in order to properly support and maintain this new large-scale architecture.
From my experience, working with enterprise networks and leading teams that manage large-scale architecture, success can be distilled down to these 4 components:
- Baseline
- Documentation
- Collaboration
- Automation
Out of the box, this all just looks like work. A lot of work. Work that no one wants to take on. It will take time, but this is the under-the-hood work that needs to be done to make your architecture run well for the long haul.
Baseline
Having a defined starting point is critical. There could be many baselines within a fine-tuned architecture. A baseline in this context is really a defined set of instructions, values, conditions, and resources that will be used to deploy a new cloud account.
An organization could maintain a different baseline for the deployment of different types of accounts. For example, a different set of instructions for a department-specific account verses an application account. The baseline for what a development account looks like in comparison to a production account should definitely be different.
The key here with a baseline is they are fixed. Not that they cannot change and evolve over time, but once you’ve initiated the deployment of an account or process, the current baseline version will be followed through until completion. Organizations will evolve, grow, and prune their baselines over time. They are not set in stone.
Benefits of baselines
A well-defined baseline helps everyone within the team or organization know and understand the definite starting point for a project or resource. Baselines also allow developers and operators to set expectations on what is or should be present in every account allowing for automation and scalability. This four-letter acronym, RECD, helps describe the benefits.
Repeatability
When creating a baseline, deploying the exact same thing every time inherently becomes the norm. This allows solutions that are developed for a single account to scale to many. With the concept of repeatability, you have a cookie-cutter deployment model where operations know exactly how to deploy or maintain an account so developers can find or use whatever they need in the exact same place no matter what account they are in.
Evolution
Because architecture baselines should be deployed with coded templates, your organization will have a documented history of how the environment has evolved over time. This is important to help the organization understand where they may have gained or lost efficiencies and be able to adjust accordingly in the next iterations. If a key component to your baseline is removed because it may be viewed as no longer necessary, you will have a historical record to reference if that component ever needs to be reintroduced.
Compliance
It’s hard to imagine a space any more where there isn’t some level of regulation dictating what or how you should be doing something. Even if it is only from your internal security team, baselines allow operations to better provide compliance information as well as maintain a more secure architecture. Critical security configurations should be near-identical across all accounts as a result of being deployed with a baseline. As stated earlier, having confidence that something is configured in a specific way in a specific location is paramount to being able to gather compliance information as well as make bulk modifications.
Destruction
Knowing that the steps to recreate something identically if need significantly reduces re-work. Having a baseline means you can (in most cases) completely tear-down something that seems to be causing issues. Maybe someone made a configuration change out-of-band. Being able to recreate and environment the exact way it’s supposed to be in short order increases the ability to simply cut-bait when something isn’t working as it should.
It’s cyclical
There are many benefits to having baselines with regards to your environment. We really can’t come up with a scenario where not having a baseline would be a net positive. Even baselining a development sandbox enables cost reduction and more secure testing practices.
Creating baselines, however, does come at a cost. Documentation is critical to maintaining robust baselines.
Documentation
It should come as no surprise that in order to support and maintain a large-scale multi-account cloud architecture requires documentation. But it might not be the type of documentation you are thinking. Granted the skill level, experience, and tenure of your operators and developers will at times determine how detailed your documentation needs to be.
Because of the vast majority of your architecture and deployment of that architecture should be in coded templates, there is no need to create seemingly endless numbers of detailed SOPs containing hundreds of steps and dozens of screenshots. Your documentation for this type of architecture should be very basic and enable autonomy. The templates and scripts should be well commented on. The logical and agreed-upon naming convention goes a long way. Lastly, less documentation of higher caliber enables more reuse. If a significant amount of context is required to understand a process, your repeatability is reduced greatly.
Naming convention & standards
Determining upfront what the labels, names, and variables for resources and processes within your environment should look like is critical to maintenance success. Having a system for naming ‘things’ is not only important for information gathering but it is a necessity in order to make mass modifications at scale.
Have documentation that lays out what names of resources should look like. Agree on what Snake case, Camel case, Kebab, and many others should look like for each category. Use different standards for different resource types.
Avoid redundancy. There are some (very few) cases where (especially in AWS) you need to include the type of the resource in the name of the resource. This is especially true when the people caring the most about the resource works mainly in the console. The is no need to name your Development VPC – DevVPC.
Layout the key labels required. What are the minimum pieces of information a resource should have to tell an admin, developer, or operator what the resource if for, what level of protection it needs, and how long it should be allowed to live?
Procedural
Mapping out the steps to deploy a solution template does not need to include every input for every field. In fact, it shouldn’t include any. Your steps should be type-o proof. We’ll discuss in a different series about automation. Anyone present in your environment after 6 months of spinup time should be able to glean the information required to conduct any process with the vaguest of steps.
Any process should have the minimum amount of detail required to successfully conduct. Only add clarification and additional details where required AFTER a step in the process has failed or been misinterpreted by more than one individual. This is an indication that more clarity may be required. However, do not add this information to the master procedure. When possible, abstract additional detailed steps to a separate document and reference that document from the primary instructions.
The key to solid documentation for maintaining a robust baseline and deploying secure and manageable architecture is simplicity. Maintaining up-to-date documentation can be very difficult. The information may be continually changing. Get as close to the process without introducing confusion and misinformation. No information is much better than incorrect information. Especially with regards to deploying critical infrastructure.
Location of information
Documentation that describes mindset, mentality, and the logic behind an organization’s process is more important in most cases than the information itself. Create resources that enable autonomy and decision making at the lowest level. When there are already agreed-upon naming conventions and procedural understandings within the organization, support and maintenance move faster.
Share instructions on how to use the organizational standards to get the information that is required. Documentation for the sake of having a process documented is worthless if no one is going to follow the steps. Document only the situations where manual intervention is required and could most likely cause a discrepancy. This would be ‘custom settings’, one-off configurations, or dependencies. The bulk of your documentation should represent where and how to find the required information when it is needed – not demonstrate the precise steps required. Parameterize and use variables in your documentation as much as possible to scale with your architecture.
Collaboration
Communicate between teams the standards, conventions, and procedures frequently. At a reasonable frequency for your organization, get together and discuss what is/not working for all stakeholders.
Any opportunity to reduce the back and forth between developers, administrations and operators will significantly impact the supportability and maintainability for the positive. If teams become annoyed or upset about something, it is important to understand why and agree on corrective action before groups begin drifting from the standard or coming up with their own processes.
Collaboration enables team cohesion, builds comradery, and further reduces the requirement for over detailed documentation. The idea is to build a culture that supports large-scale architecture. Not one that sabotages it.
Automation
About as obvious as documentation is automation. If manual intervention is a requirement for many steps in an architecture deployment, one could imagine at some point in the scaling process, systems begin to break down.
Automate anything that you can that happens more than once. Automation is a form of documentation. The appropriate process for automating something should include commented code and the ability to logically follow a process in case that process were to ever break down.
Automation does so much more than shave seconds or minutes off the front end of a process. As we stated earlier, it is important to enable autonomy. Automation does this. The more cogs you have in a process, the more potential for things to go wrong or steps to get missed.
Even a simple process, that only takes a minute or two, conducted weekly could have a profound impact on the amount of rework it could cause if the process is completed incorrectly and deploys or configures a resource incorrectly. Remember, the naming convention is critical for the ability to make a mass modification at scale. If the individual responsible for the process does so incorrectly or misses the process entirely due to a busy schedule or absence, considerable harm to your architecture could result.
Automation doesn’t completely eliminate human error; however, it can significantly reduce it.
Tools, 3rd-party solutions, & systems
As a bonus or honorable mention, it is important to state that these four components for successfully supporting and maintaining MMA have some sort of tool, service, or system behind them.
How you conduct your automation and where you store your documentation is considerably less important than actually having these components as a solid part of your foundation. However, it would be impossible to support and manage this type of architecture without an array of different tools. This series and this specific post is not the place to share the many options available.
Each organization will also be very different than the next with regards to their preferred tools and systems for deployment. Budget, technical competency, time resources, etc. all factor into what should be considered a viable solution for each architecture.
Check back to Tactful Cloud frequently for updates and information on the tools and solutions that are available to meet your support and maintenance requirements.
Series parts are as follows:
-
- Series Introduction
- My experience with Multi-Account Architecture
- What does the end-state look like
- Reasons you might consider multi-account architecture
- When it is right to implement
- What the potential architecture might look like
- How do you get there
- How do you support and maintain the architecture
- Lessons learned