 https://tactful.cloud/wp-content/uploads/2020/02/MAA-Experience-1.png
1200
2133
cloudman444
https://tactful.cloud/wp-content/uploads/2026/02/tactful_cloud_logo1_dark1.png
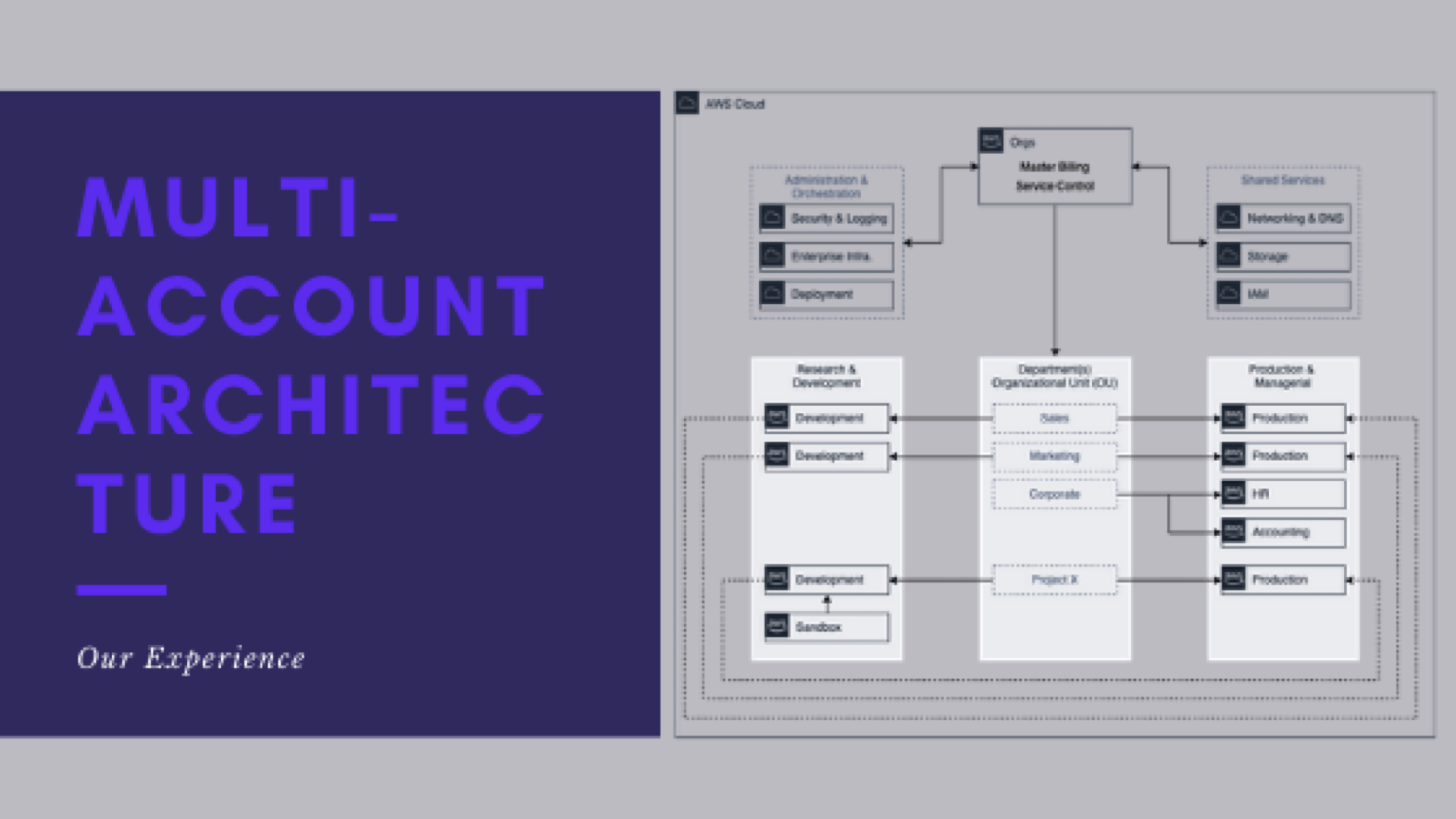
cloudman4442026-02-10 06:30:002026-02-12 16:40:12My experience with Multi-Account Architecture
https://tactful.cloud/wp-content/uploads/2020/02/MAA-Experience-1.png
1200
2133
cloudman444
https://tactful.cloud/wp-content/uploads/2026/02/tactful_cloud_logo1_dark1.png
cloudman4442026-02-10 06:30:002026-02-12 16:40:12My experience with Multi-Account Architecture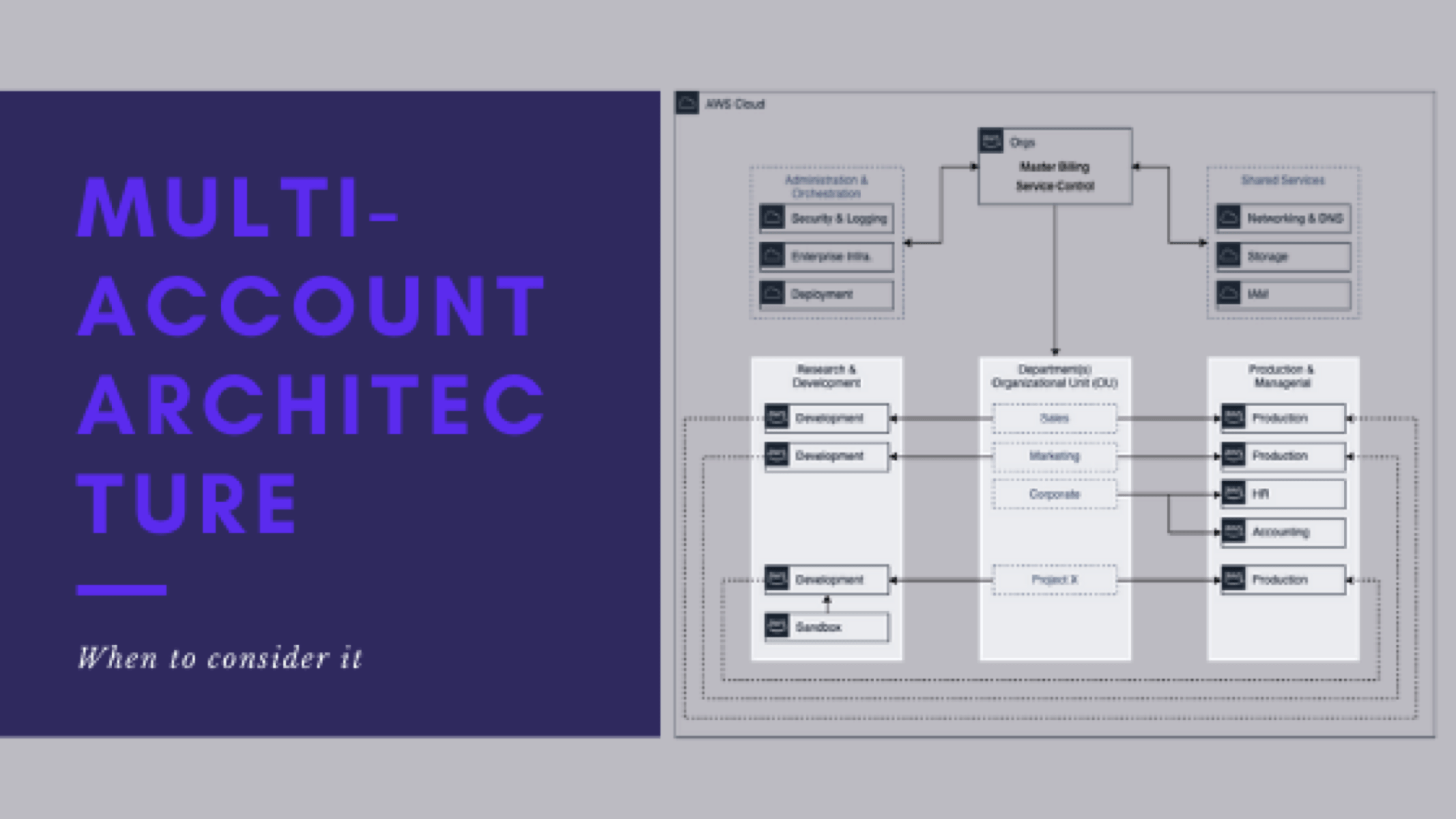 https://tactful.cloud/wp-content/uploads/2020/02/MAA-Consider-1.png
1200
2133
cloudman444
https://tactful.cloud/wp-content/uploads/2026/02/tactful_cloud_logo1_dark1.png
cloudman4442026-01-24 06:30:002026-02-12 16:41:39When to consider a multi-account architecture?
https://tactful.cloud/wp-content/uploads/2020/02/MAA-Consider-1.png
1200
2133
cloudman444
https://tactful.cloud/wp-content/uploads/2026/02/tactful_cloud_logo1_dark1.png
cloudman4442026-01-24 06:30:002026-02-12 16:41:39When to consider a multi-account architecture?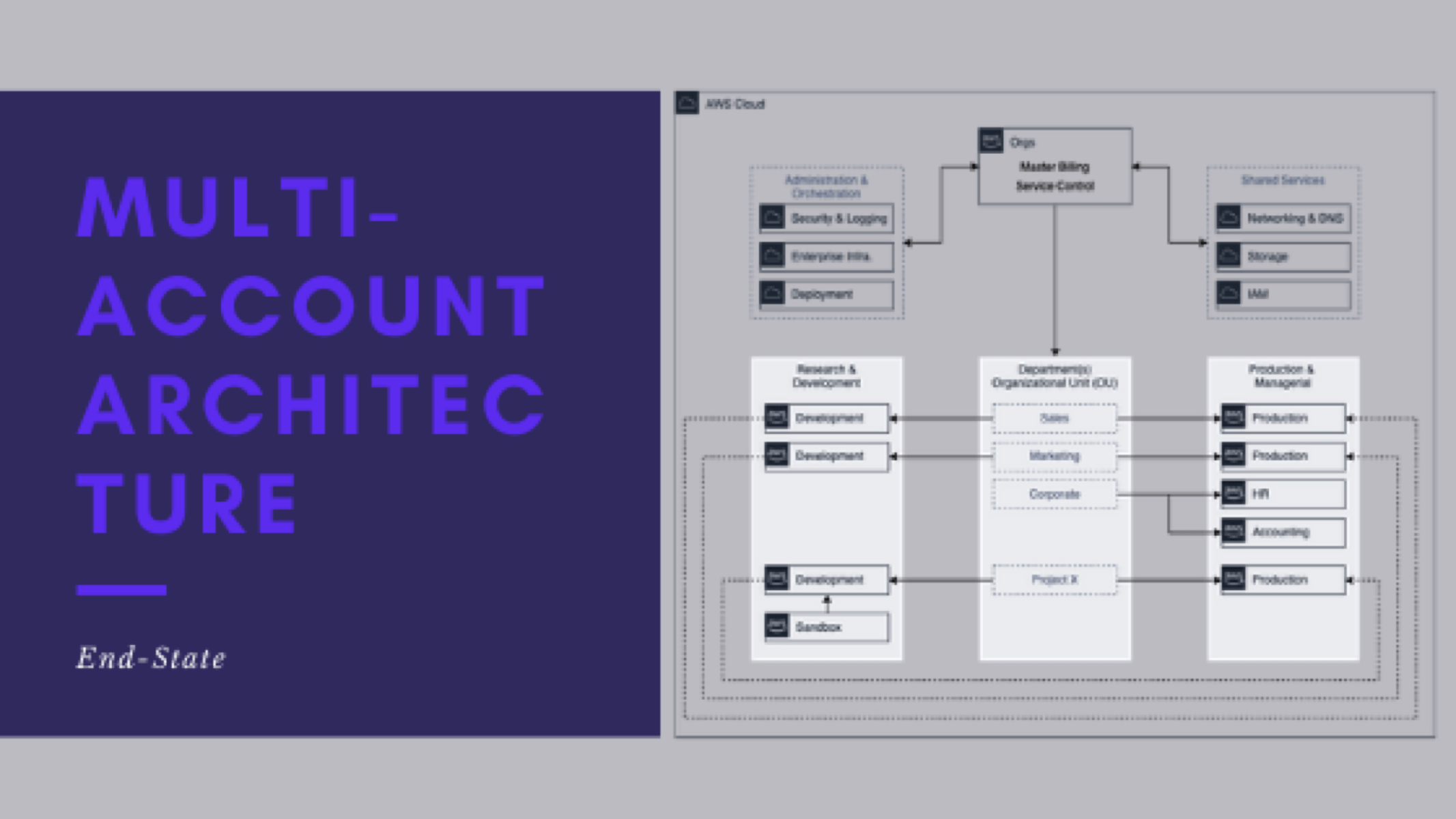 https://tactful.cloud/wp-content/uploads/2020/02/MAA-End-State-1.png
1200
2133
cloudman444
https://tactful.cloud/wp-content/uploads/2026/02/tactful_cloud_logo1_dark1.png
cloudman4442026-01-17 06:30:002026-02-12 16:41:49Multi-Account End-State
https://tactful.cloud/wp-content/uploads/2020/02/MAA-End-State-1.png
1200
2133
cloudman444
https://tactful.cloud/wp-content/uploads/2026/02/tactful_cloud_logo1_dark1.png
cloudman4442026-01-17 06:30:002026-02-12 16:41:49Multi-Account End-State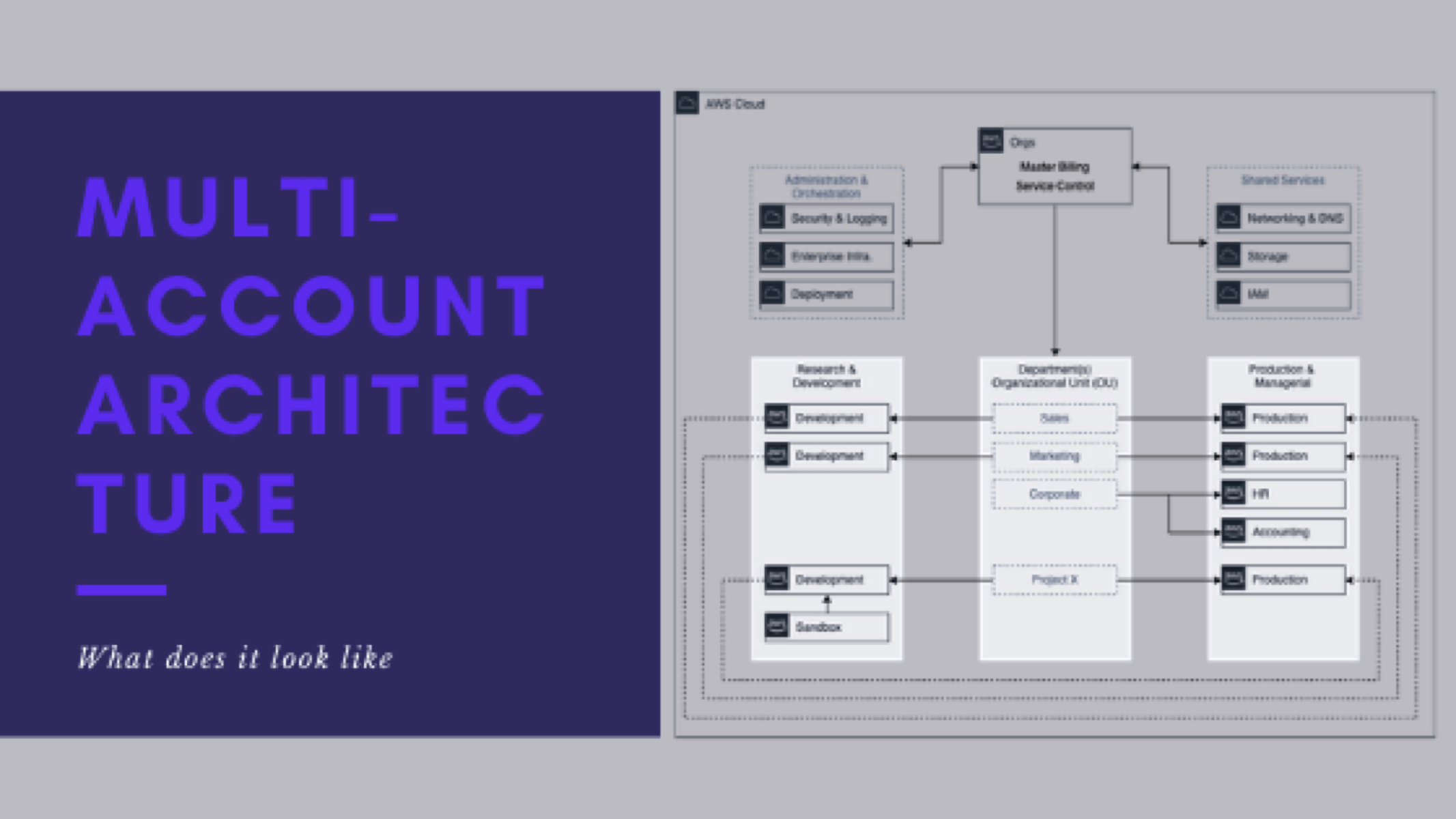 https://tactful.cloud/wp-content/uploads/2020/03/MAA-Design-1.png
1200
2133
cloudman444
https://tactful.cloud/wp-content/uploads/2026/02/tactful_cloud_logo1_dark1.png
cloudman4442026-01-09 06:30:002026-02-12 16:39:31What a multi-account architecture might look like
https://tactful.cloud/wp-content/uploads/2020/03/MAA-Design-1.png
1200
2133
cloudman444
https://tactful.cloud/wp-content/uploads/2026/02/tactful_cloud_logo1_dark1.png
cloudman4442026-01-09 06:30:002026-02-12 16:39:31What a multi-account architecture might look like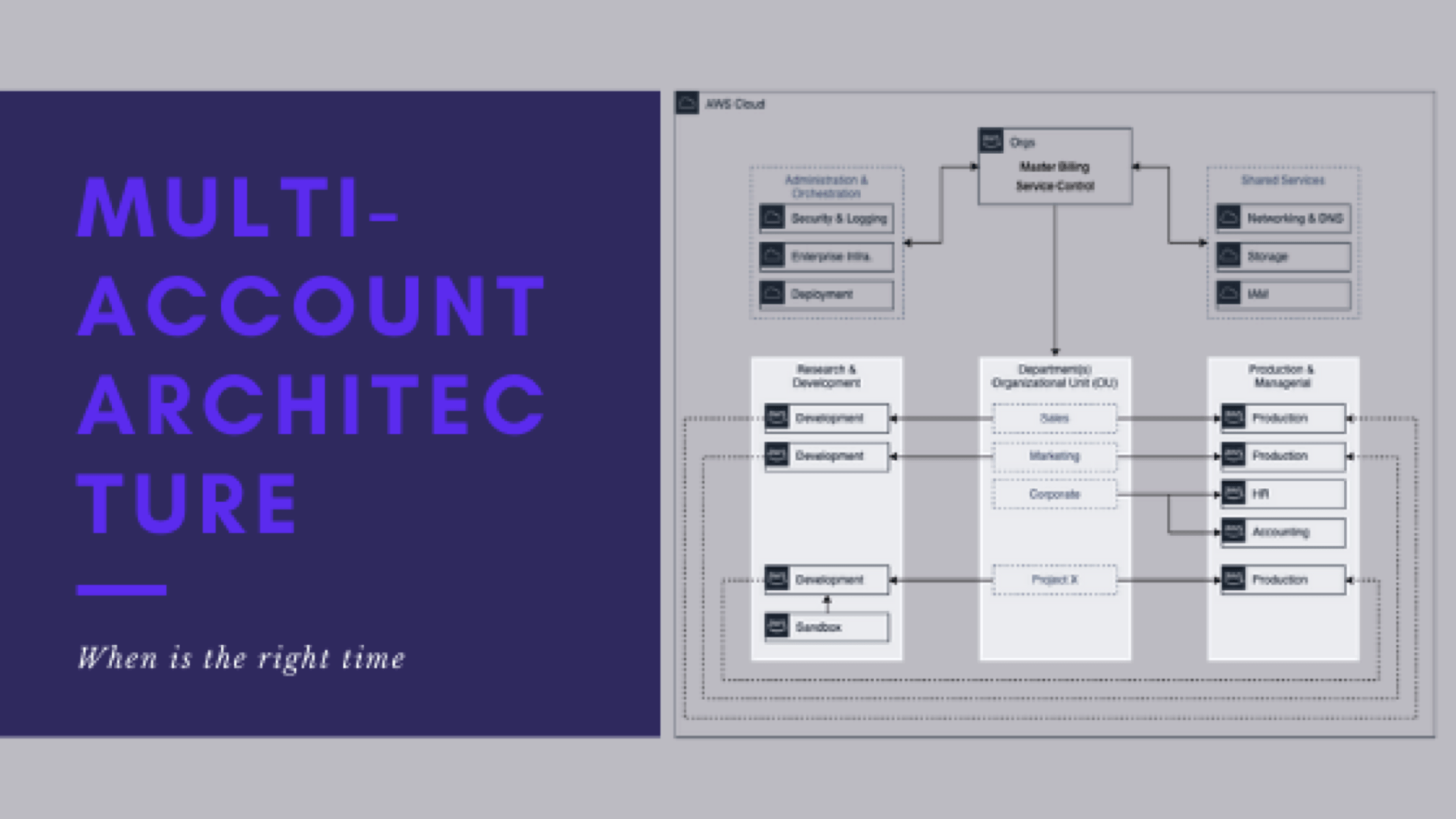 https://tactful.cloud/wp-content/uploads/2020/03/MAA-Timing-1.png
1200
2133
cloudman444
https://tactful.cloud/wp-content/uploads/2026/02/tactful_cloud_logo1_dark1.png
cloudman4442026-01-02 06:30:002026-02-12 16:39:42When is it right to implement a multi-account architecture
https://tactful.cloud/wp-content/uploads/2020/03/MAA-Timing-1.png
1200
2133
cloudman444
https://tactful.cloud/wp-content/uploads/2026/02/tactful_cloud_logo1_dark1.png
cloudman4442026-01-02 06:30:002026-02-12 16:39:42When is it right to implement a multi-account architecture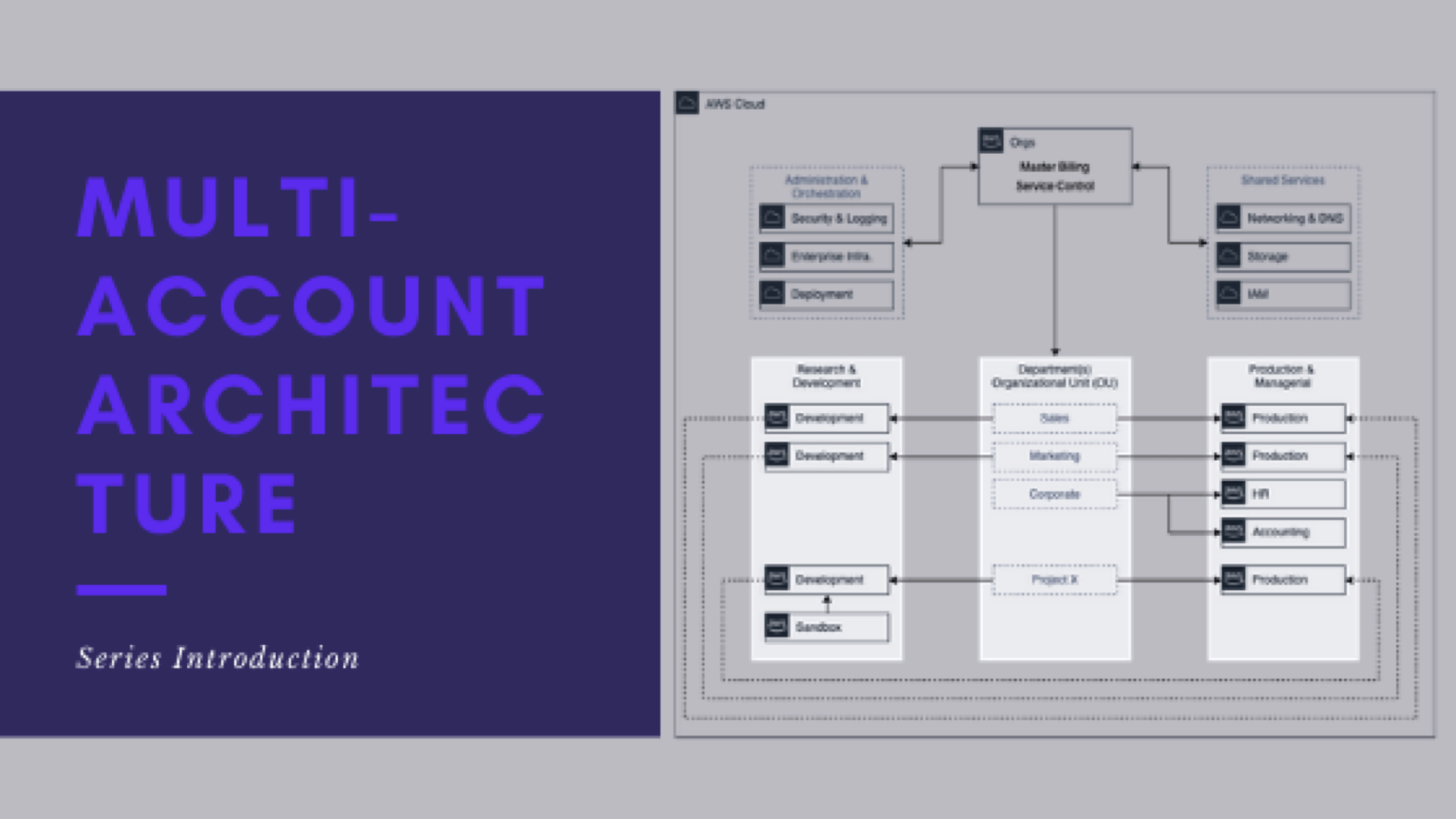 https://tactful.cloud/wp-content/uploads/2020/02/MAA-Introduction-1.png
1200
2133
cloudman444
https://tactful.cloud/wp-content/uploads/2026/02/tactful_cloud_logo1_dark1.png
cloudman4442025-10-03 06:30:002026-02-12 16:40:26Multiple Cloud Account Architecture (Series)
https://tactful.cloud/wp-content/uploads/2020/02/MAA-Introduction-1.png
1200
2133
cloudman444
https://tactful.cloud/wp-content/uploads/2026/02/tactful_cloud_logo1_dark1.png
cloudman4442025-10-03 06:30:002026-02-12 16:40:26Multiple Cloud Account Architecture (Series)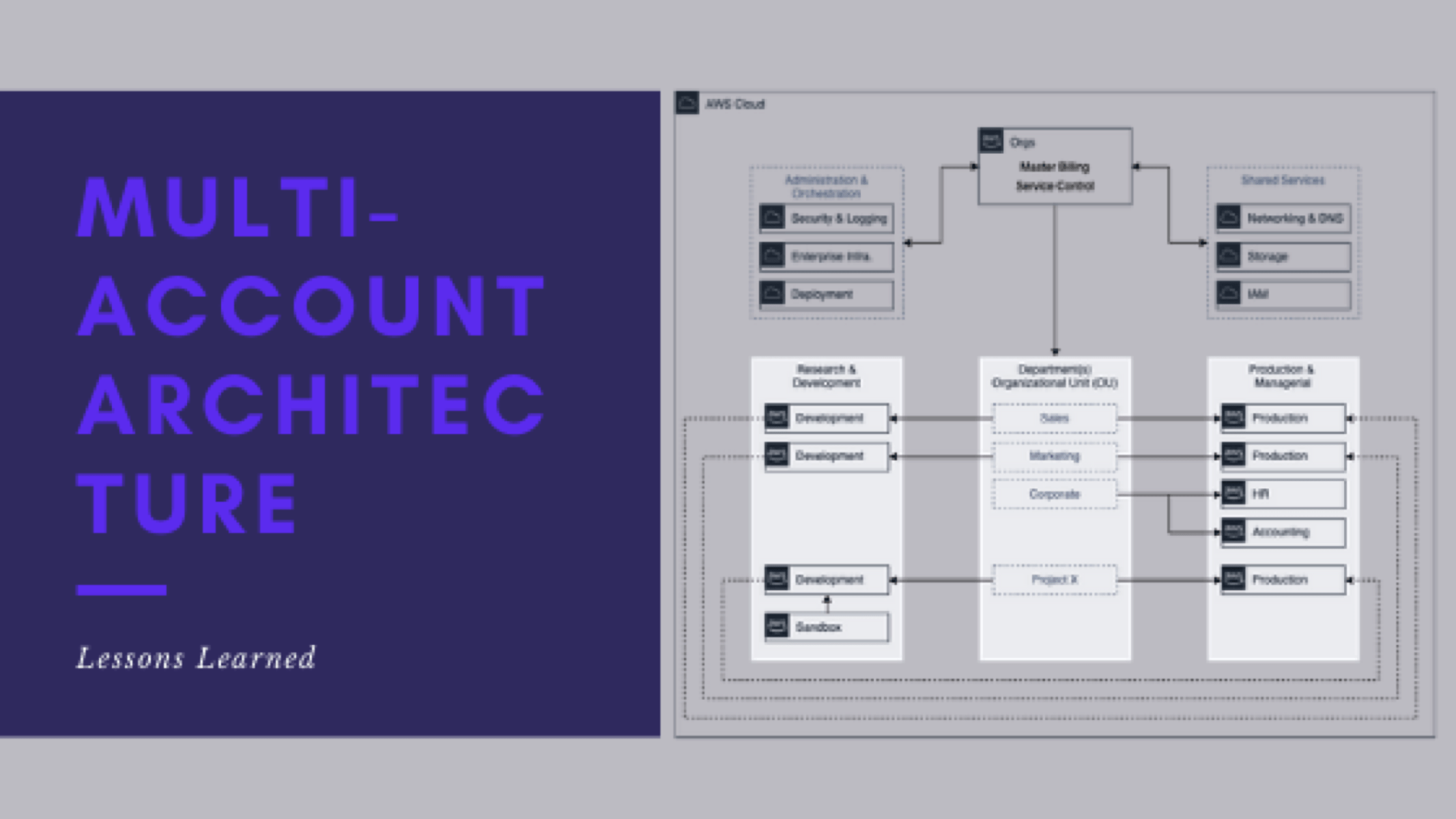 https://tactful.cloud/wp-content/uploads/2020/03/MAA-Lessons-Learned-1.png
1200
2133
cloudman444
https://tactful.cloud/wp-content/uploads/2026/02/tactful_cloud_logo1_dark1.png
cloudman4442025-03-30 06:30:002026-02-12 16:39:02Lessons learned around multi-account architecture
https://tactful.cloud/wp-content/uploads/2020/03/MAA-Lessons-Learned-1.png
1200
2133
cloudman444
https://tactful.cloud/wp-content/uploads/2026/02/tactful_cloud_logo1_dark1.png
cloudman4442025-03-30 06:30:002026-02-12 16:39:02Lessons learned around multi-account architecture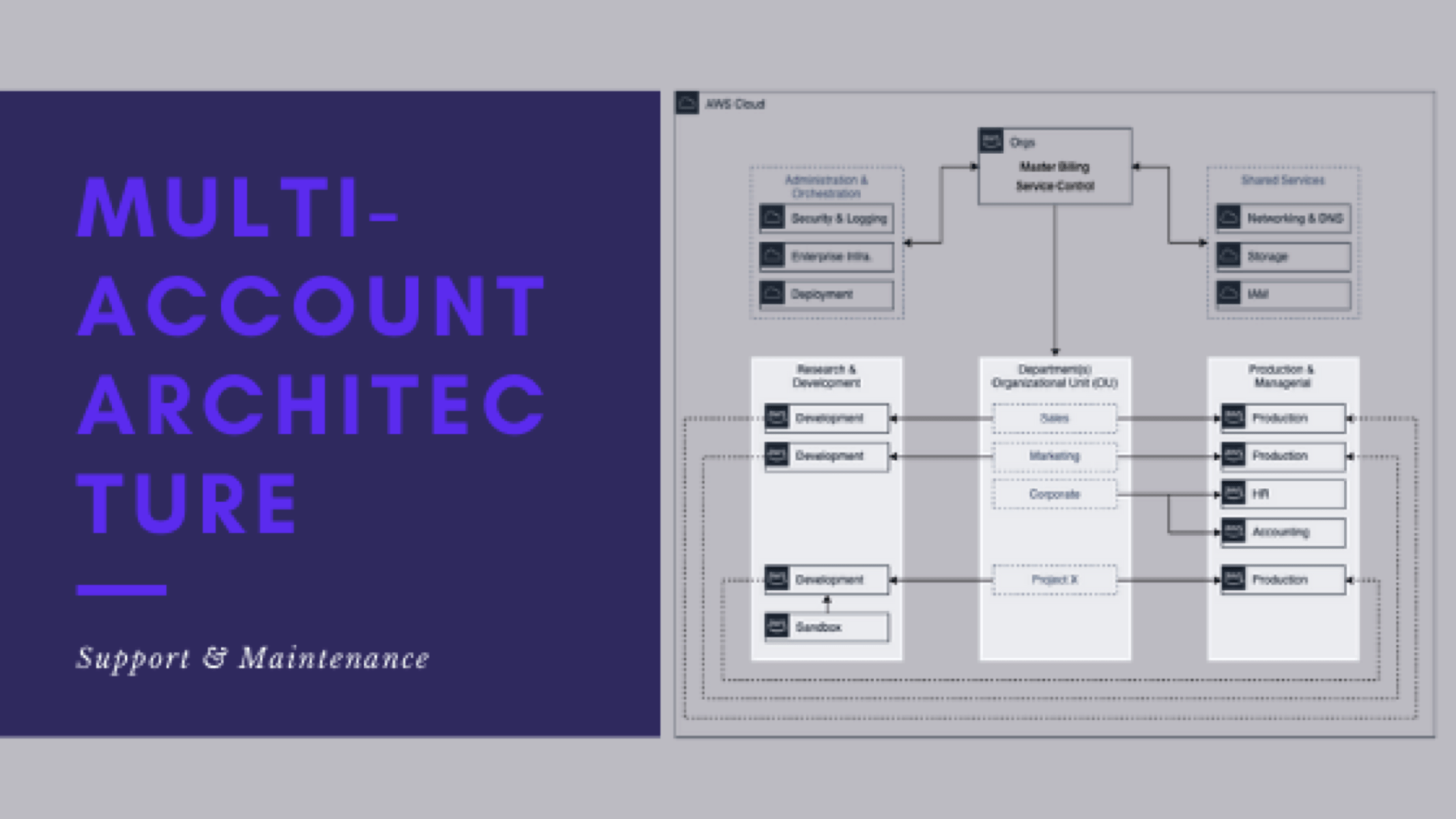 https://tactful.cloud/wp-content/uploads/2020/03/MAA-Support-Maintenance-1.png
1200
2133
cloudman444
https://tactful.cloud/wp-content/uploads/2026/02/tactful_cloud_logo1_dark1.png
cloudman4442025-03-23 06:30:002026-02-12 16:39:11Support and maintenance of multi-account architecture
https://tactful.cloud/wp-content/uploads/2020/03/MAA-Support-Maintenance-1.png
1200
2133
cloudman444
https://tactful.cloud/wp-content/uploads/2026/02/tactful_cloud_logo1_dark1.png
cloudman4442025-03-23 06:30:002026-02-12 16:39:11Support and maintenance of multi-account architecture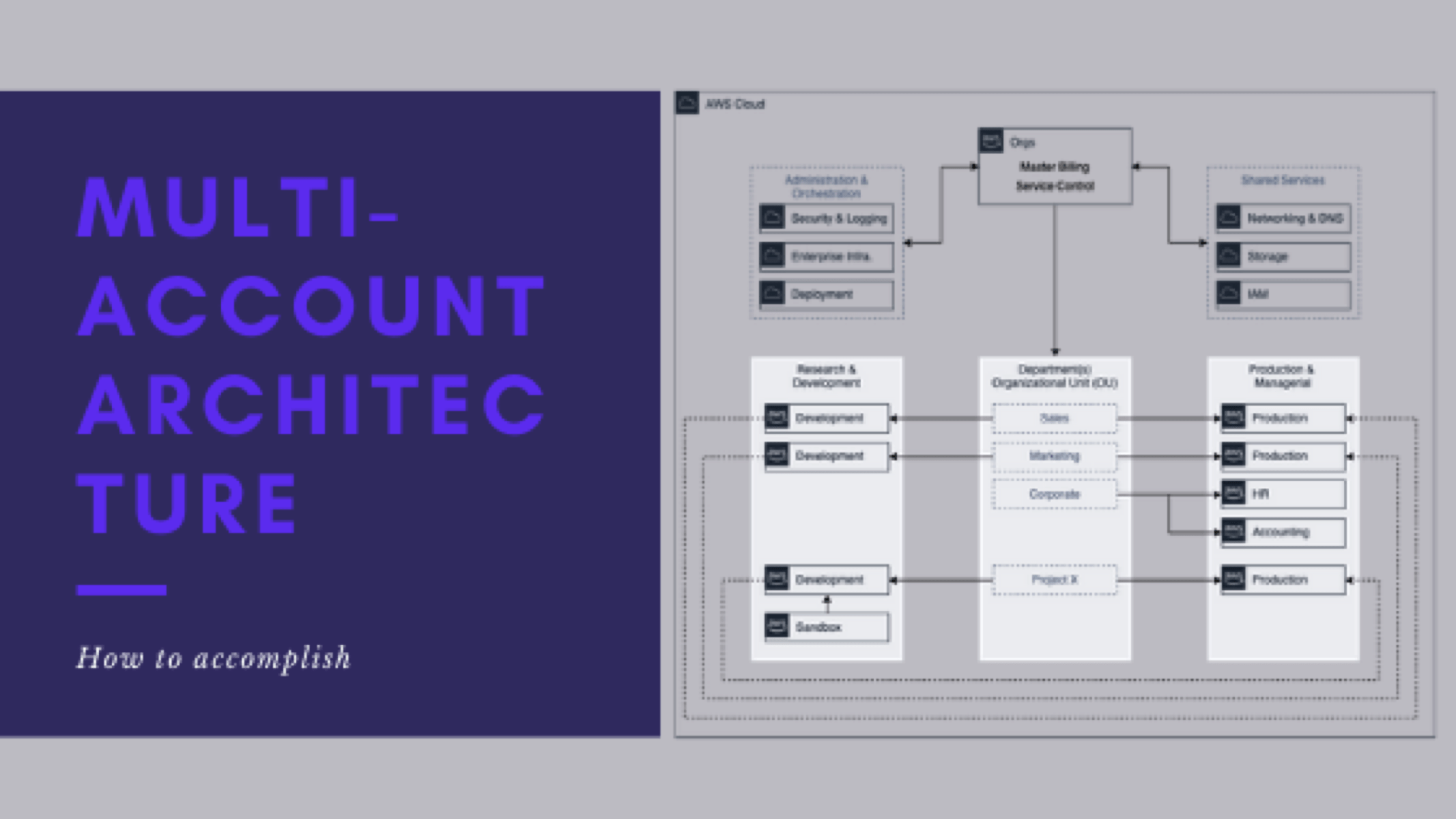 https://tactful.cloud/wp-content/uploads/2020/03/MAA-Accomplish-1.png
1200
2133
cloudman444
https://tactful.cloud/wp-content/uploads/2026/02/tactful_cloud_logo1_dark1.png
cloudman4442025-03-16 06:30:002026-02-12 16:39:19How to accomplish a successful multi-account architecture
https://tactful.cloud/wp-content/uploads/2020/03/MAA-Accomplish-1.png
1200
2133
cloudman444
https://tactful.cloud/wp-content/uploads/2026/02/tactful_cloud_logo1_dark1.png
cloudman4442025-03-16 06:30:002026-02-12 16:39:19How to accomplish a successful multi-account architecture