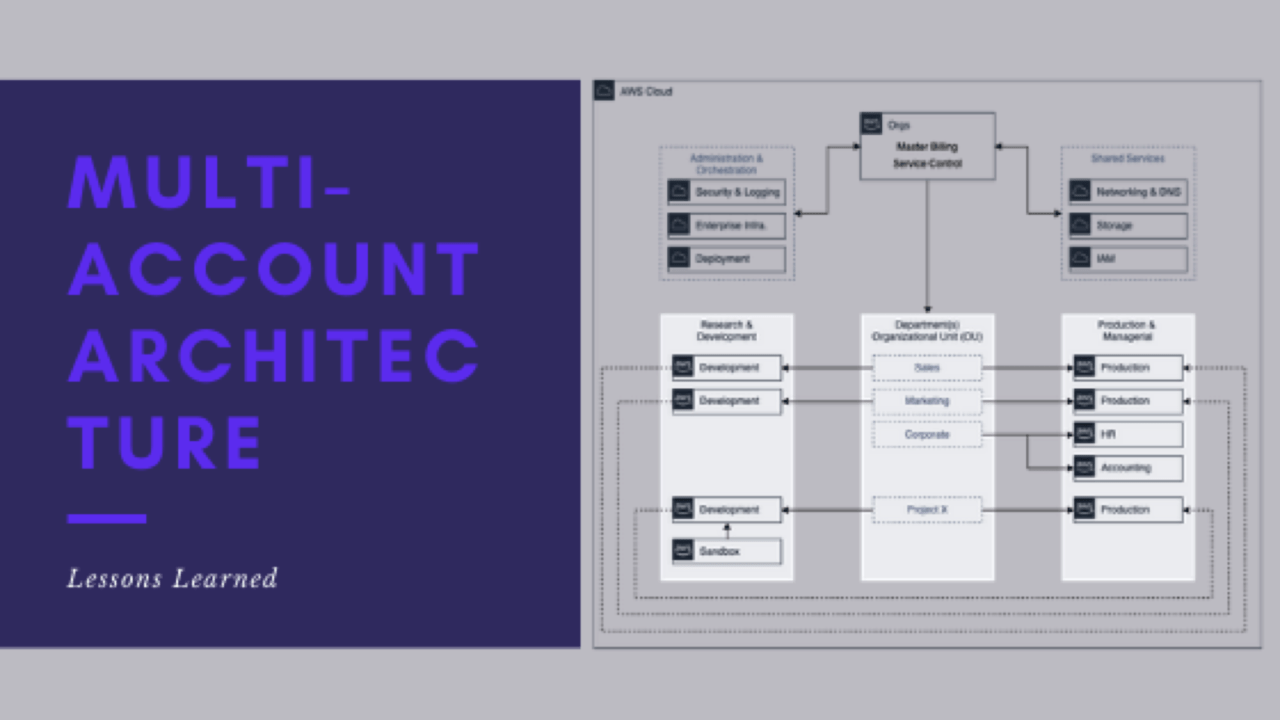
Lessons learned around multi-account architecture
This is post 9 of 9 in a multi-part series (hosted here) discussing the advantages, pitfalls, deployment methodology, and management of a multi-cloud account architecture. For this series, we are focusing strictly on using AWS as the Cloud Service Provider (CSP) but the concepts discussed port well to any provider or even to on-premise operations.
Wear a helmet
No matter how prepared you are to start this process, you’re going to take some lumps along the way. No amount of technical skill or understanding of the provider services will prevent you from going deep in a direction only to complete it just before the release of a service enhancement that may have done all of the work for you. Fortunately, service enhancements or additional features that might be responsible for something like this happening have significantly slowed down as the providers mature. This is why we stated earlier on that it is important where possible to use the provider recommended solution over a different solution. Wait if you can. It is likely something on the roadmap.
There will be times when you hit an un- (or not so well) documented limitation that will require your organization to get creative to meet requirements. This is almost completely unavoidable. The important thing is to stay flexible, design with the future in mind, document as described in a previous post, and automate as much as possible.
Think of this entire process with regard to software development. The deployment model for your architecture is essentially backed by code. Being ‘agile’ and leveraging brief release cycles and make adjustments over time. Rather you’ve landed in a single cloud provider or are spread out in hybrid-cloud, think about the ‘software development lifecycle‘ and treat your architecture the same way. Every few years or even months there will come a time to re-evaluate and re-deploy services leveraging the latest and greatest services and standards based on current industry best practice.
Start small
Consider compartmentalizing some of the most basic functionality. It is possible to de-couple too much creating more work for yourself, but it is much easier to add in than remove. It is important to iterate slowly over time. Or if you need to move a little bit faster, include many small calculated changes in your infrastructure that don’t create a whole bunch of dependencies if you don’t have to.
Automation enables small iterative change to many solutions at scale. If your deployment process is part of a CICD pipeline you have the ability to easily make multiple changes a day and rollback to previous configurations if needed at any time.
Working in small iterative chunks allows you to better keep an eye out for potentially destructive operations. In many situations, especially with AWS, certain modifications of resources actually result in a total replacement of the resource changing unique identifiers and/or breaking dependencies for other deployed resources. More often than not these operations will fail as a result of being dependent or depended upon but this is why you should be very considerate of everything you deploy, in what order, and with what other resources.
Test everything
In the solid foundation that you should have already laid out to this point, there should have been included a test environment. This is the account where you keep a working copy of everything that is deployed into your mission-critical accounts. If you can keep an up-to-date version of every mass-deployed resource in this account, you should be able to avoid major mishaps when it comes time to deploy and terminate solutions across your MAA. This account is critical for testing the removal of resources and creating procedures or scripts that will help you clean up or recover from a situation where you didn’t have your resources as de-coupled as you had hoped.
Plan for scale
Rather you are shooting for 4 accounts or 100, it is important to design solutions with reuse in mind. This means parameterizing as much as possible. Hardcoding names, identifiers, and other unique variables will lead to additional and unnecessary work.
Don’t build something yourself if there is already a solution available. This is important to consider for smaller organizations thinking they are going to save a few bucks. Your custom solutions most likely won’t scale the way you need when growth starts happening organically. Once your foundation is laid and systems in place, you will be surprised how quickly your architecture will scale. Maintaining and updating home-bake solutions to meet your architecture needs will quickly become very cumbersome if not impossible.
Expect the unexpected
Regardless of the CSP you go with, there will be nuance upon nuance with how the provider operates. Things you couldn’t possibly have planned for or thought of will creep up causing you to reevaluate your entire deployment model. Expect the unexpected. Treat your architecture like software and create newer versions of it over time to correct for the things you didn’t realize at the time were going to be an issue.
Feedback and flexibility
Communicate openly and honestly about the pros and cons of a particular deployment decision with all stakeholders. It is likely the person responsible for the creation of a new process or solution isn’t seeing everything from all angles. No single developer or operator in your organization can be responsible for accounting for every gotchya.
Everyone has blindspots. If you are the one responsible for the deployment of a new process or solution that is supposed to optimize ‘X’, be ready for your team to look at your solution critically and provide feedback or criticism. It is everyone’s responsibility to do what is in the best interest of the organization. With regard to cloud technology, there are at least a half dozen ways to accomplish anything. Be flexible and accepting of their feedback and do not take it personally.
Wrapping up
In this series, we’ve covered a whole lot. Everything from why an organization would even want to bother with all the extra work of establishing a multi-account cloud architecture, what one would look like, when the right time to implement is, how to best support MAA at scale, and now some of the lessons learned.
We sincerely hope you’ve enjoyed this series and we look forward to your feedback. We would also appreciate you sharing your opinions and stories regarding your current or projected future cloud architecture.
AWS Control Tower v. Landing Zones
As we were preparing this series, it was requested we provide a comparison between two AWS native service offerings designed to help streamline and manage this entire process. We have that in the works currently so check back often for that post.
Content & Resources
We are also in the process of polishing up an online course that better details all of the steps for creating the AWS Organizations foundation for a successful multi-account architecture that we have discussed in this series.
Series parts are as follows:
- Series Introduction
- My experience with Multi-Account Architecture
- What does the end-state look like
- Reasons you might consider multi-account architecture
- When it is right to implement
- What the potential architecture might look like
- How do you get there
- How do you support and maintain the architecture
- Lessons learned








Leave a Reply
Want to join the discussion?Feel free to contribute!